Puzzle: Efficiently Aligning Large Language Models through Light-Weight Context Switch
简介
这篇工作主要优化 PPO 训练过程。典型的 PPO 算法如下:
使用 PPO 算法训练时,涉及四个模型( Actor, Critic, Reference, Reward )以及三个阶段。具体流程为:阶段一,首先输入 prompt,由 actor 根据 prompt 生成 response;阶段二,然后将 prompt 和生成的 response 拼在一起生成 experiences,同时过 Reference, Reward, Critic 模型;阶段三,根据相关结果计算 loss ,然后更新 Actor, Critic 的权重(即 Reference 和 Reward 模型的权重是冻结的)。最终将 Actor 作为输出模型。
作者观察到在使用 PPO 算法的训练过程存在以下两个特征:
- 模型结构以及计算负载的异构性: 四个模型可能不太相同,带来不同异构性; 整个过程有推理,有训练,给计算负载也带来异构性。
- 频繁的“上下文交换”: 不同阶段(阶段之间相互依赖)涉及不同模型参与计算,需要切换上下文;阶段内可能也需要切换上下文。例如先计算 Reference, Reward 然后计算 Critic(尽管这三个计算没有依赖,可能高效的并行算法需要这样做)。

作者认为当前的训练系统存在以下限制:
- 只针对单个模型进行优化。忽略了不同模型之间协调工作的场景。
- 忽略了不同工作负载带来的问题。例如只考虑训练并行和推理并行,而当这两种并行使用的方案不同,就涉及到“上下文”切换,从而带来额外开销。
作者主张从两个视角进行优化:Intra-Stage 和 Inter-Stage 视角进行优化。 也即是考虑 Stage 内的优化和 Stage 间的优化。
评论:本质看下来还是单点优化, intra-stage 的优化和 inter-stage 的优化还是单独讨论的。只有降低这两个阶段开销整体开销就变小。如果联合考虑 intra-stage 和 inter-stage 这个问题更 fancy ,但是求解空间会变大,变负载。
Intra-Stage
Stage 内,例如阶段二,三个模型之间是没有数据依赖的,那么这三个模型就可以并行执行。典型的并行方案有如下三种:
- MBM,每个模型使用全部GPU,模型间串行执行。
- SMDD,每个模型使用部分GPU,模型间并行执行。
- MMDD,结合上面两种方法。
评价:下面这种图(d)个人感觉有点问题,并没有整体提现出工作的贡献。红色框是主张的 intra-stage 解决方案没问题。但是前面一部分并没有体现出 inter-stage 的解决方案。这时候还有一种方案,使用图 (b) 的方式做推理,然后做上下文切换,再做红框里的训练。
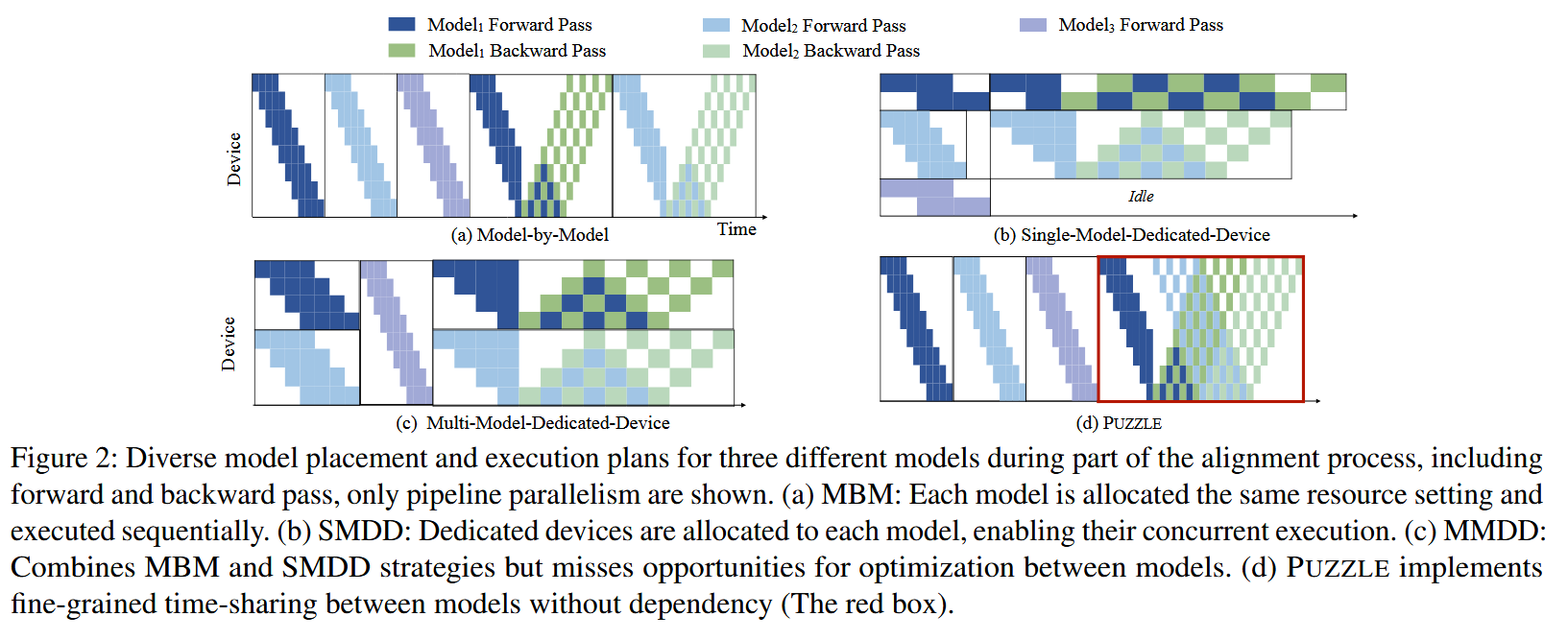
上述三种方法明显没有完全利用 GPU。因此作者主张“Time-Sharing Switching”方案。具体思路很简单如下: 由于阶段内的模型之间并没有数据依赖,在下图(a)切换上下文时,会有空闲时间(和 PP 并行中的空泡类似),那么可以利用这个时间处理下一个阶段的问题。

Inter-Stage
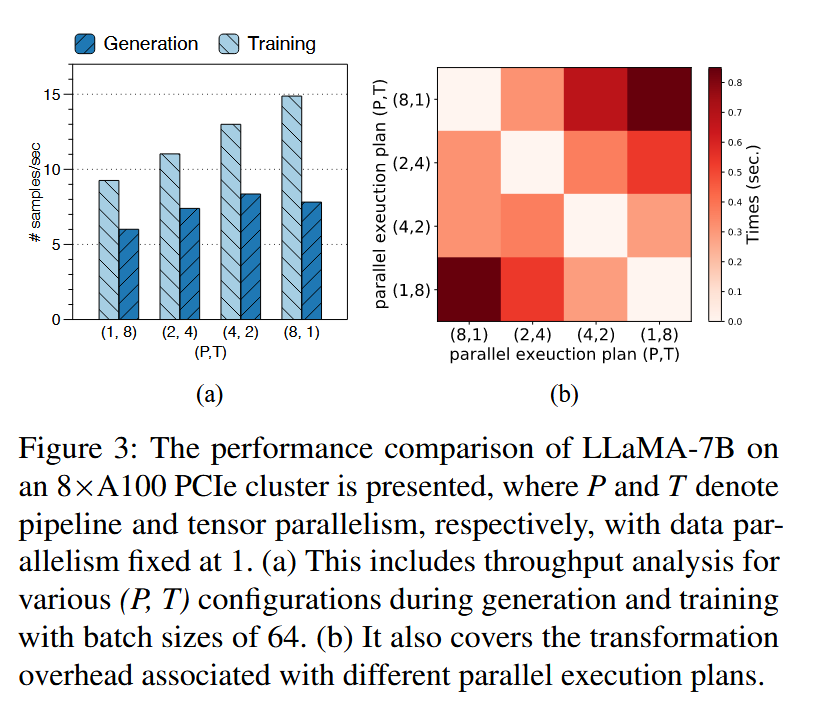
上文已经讨论过,在不同 stage 之间可能使用不同的并行方案,如��下图。例如阶段二中,Reward Model 和 Reference Model 使用 SMDD 并行策略。而 Critic 使用 MBM 并行策略。 由于并行方案不同(使用不同设备), 那么切换到对应的方案所需的开销就必须考虑。
评价:在实验章节的图12中或许Comm时间写成上下文切换开销会好点?

作者的解决方案也很简单,“Similarity-oriented”方案,也即是并行方案变化越小,开销越小,如下图所示。
评论:5.3节这一部分细节太少了,不知道这个切换成本怎么预估出来?离线还是在线拟合?